

The conversation relating to using a UniqueIdentifier for primary key comes up over and over again. The primary impetus is around it being an external identifier so that bad actors can't guess IDs based off a current value (int, long, or varchar if predictable). We're going to compare each data type. For VARCHAR we're going to use the same string value as a UUID/GUID. Note that primary keys are by default clustered indexes in MS SQL. We avoid the use of NewSequentialID() as the value for PK in UniqueIdentifier and VARCHAR tables for security reason mentioned previously.
Key Factors for a Primary Key
- Unique
- Small (preferably numeric types)
- Not subject to change. Impacts other tables that use it as a foreign key. Avoid anything that business related.
Setup
DECLARE @val INT
SELECT @val=1
WHILE @val < 100000
BEGIN
INSERT INTO test_INT (Id, col1, col3, col4)
VALUES (@val,round(rand()*100000,0),round(rand()*100000,0),'TEST' + CAST(@val AS VARCHAR))
INSERT INTO test_GUID (Id, col1, col3, col4)
VALUES (newid(),round(rand()*100000,0),round(rand()*100000,0),'TEST' + CAST(@val AS VARCHAR))
INSERT INTO test_VARCHAR (Id, col1, col3, col4)
VALUES (newid(),round(rand()*100000,0),round(rand()*100000,0),'TEST' + CAST(@val AS VARCHAR))
SELECT @val=@val+1
END
GO
You may want to adjust the count to something lower than 100000. This took about 40 minutes for me to run in a MS SQL container on a beefy machine with decent SSD.
Memory Usage
SELECT OBJECT_NAME(i.[object_id]) AS TableName,
i.[name] AS IndexName,
SUM(s.[used_page_count]) * 8 AS IndexSizeKB
FROM sys.dm_db_partition_stats AS s
INNER JOIN sys.indexes AS i ON s.[object_id] = i.[object_id] AND s.[index_id] = i.[index_id]
WHERE OBJECT_NAME(i.[object_id]) like '%Test%'
GROUP BY i.[name],i.[object_id];

The index size is the largest with VARCHAR(36) since the guid/uuid is 36-bytes including the hyphens. The UniqueIdentifier stores a 16-byte binary value.
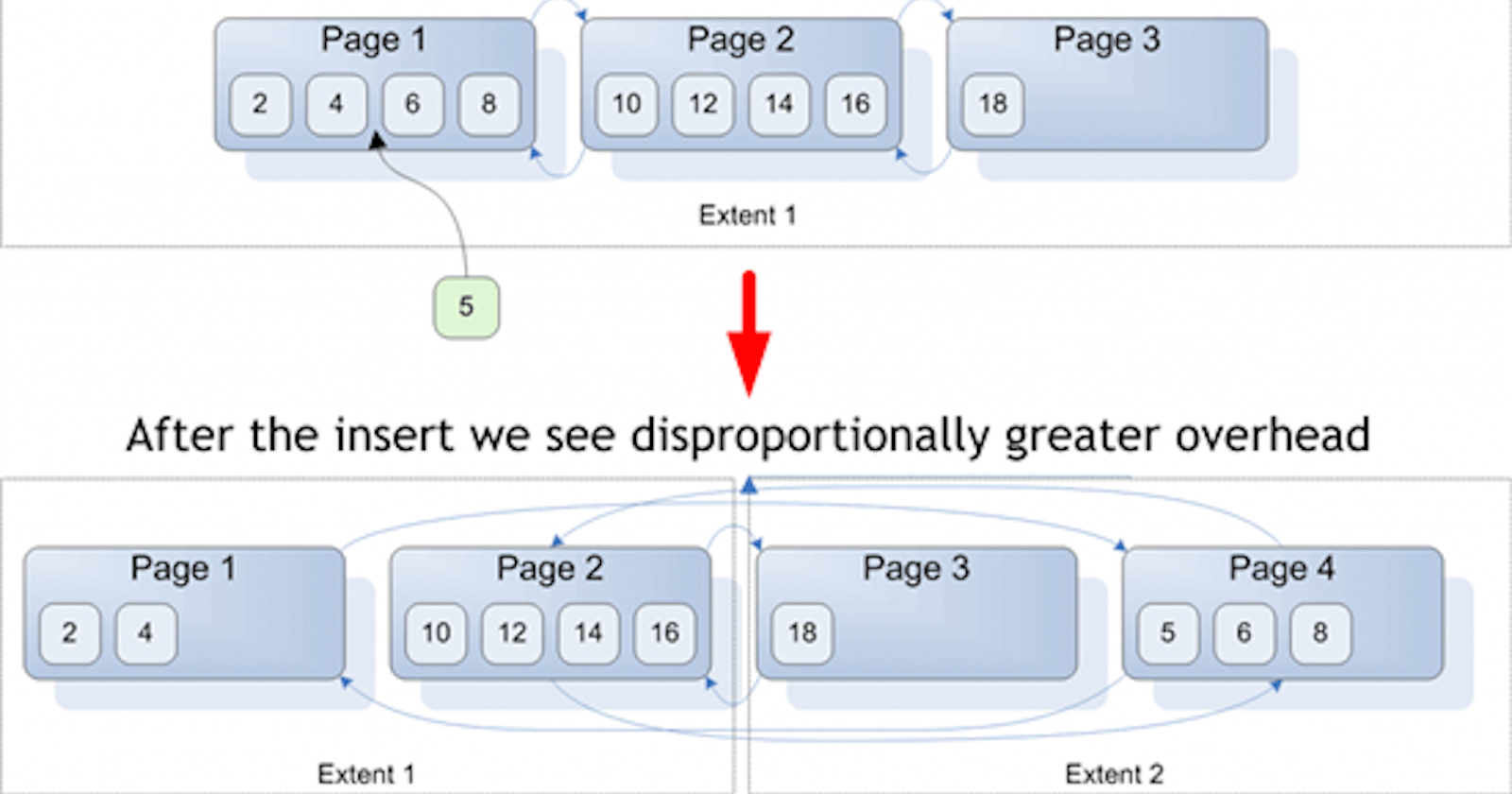
Index Fragmentation
Index fragmentation occurs when indexes have pages in which the logical ordering within the index, based on the key value of the index does not match the physical ordering inside the index pages. Underneath the covers SQL Server uses a B+ tree for the index.
Every time an insert, update or delete operation occurs, the index is updated and the time complexity is logarithmic time on average for those operations. As more operations occur this can cause the values in the index to become mixed since those indexes have pages in which the logical ordering (key/value) does not match the physical location on disk. This is external fragmentation. Even with SSDs, this fragmentation could be a concern.
Internal fragmentation occurs when a new page is added and it's close to empty. This also matters because it's another page to scan.
SELECT OBJECT_NAME(i.OBJECT_ID) AS TableName,
i.name AS IndexName,
indexstats.index_type_desc AS IndexType,
indexstats.page_count,
indexstats.avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) indexstats
INNER JOIN sys.indexes i ON i.object_id = indexstats.object_id AND i.index_id = indexstats.index_id
WHERE OBJECT_NAME(i.OBJECT_ID) like '%Test%'
ORDER BY indexstats.avg_fragmentation_in_percent DESC

Yikes, that's a high average index fragmentation percentage for VARCHAR and UniqueIdentifier. Page count also tracks. The more pages, the longer it takes to search/update the index. To be more accurate, it will depend on your hardware since below a certain number of pages, those will be cached in RAM. Above that amount, it is read from disk. 100,000 records, nbd, but order of 10^6... no bueno.
Index fragmentation can also cause changes to the execution plan which could also negatively impact performance.
To mitigate this issue, a REBUILD or REORGANIZE (defragment) operation can be done to the index. Rebuilds can be time and resource intensive. Reorganizing is faster.
Performance Impact
Values below should be replaced with actual Ids.
-- SELECT
SELECT * FROM Test_INT WHERE Id=1750
GO
SELECT * FROM Test_GUID WHERE Id='9DEE1ED9-50A8-4887-8BE7-00BCDDA28113'
GO
SELECT * FROM Test_VARCHAR WHERE Id='0095797E-2F53-43B3-9127-C00AD87440D1'
GO
-- INSERT
INSERT INTO Test_INT (Id, col1, col2, col3)
VALUES (5000001, round(rand()*100000,0),round(rand()*100000,0),'TEST' + CAST(5000001 AS VARCHAR))
GO
INSERT INTO Test_GUID (Id, col1, col2, col3)
VALUES (newid(), round(rand()*100000,0),round(rand()*100000,0),'TEST' + CAST(5000001 AS VARCHAR))
GO
INSERT INTO Test_VARCHAR (Id, col1, col2, col3)
VALUES (newid(), round(rand()*100000,0),round(rand()*100000,0),'TEST' + CAST(5000001 AS VARCHAR))
GO
-- UPDATE
UPDATE Test_INT SET col1=232342,col3=232340,col4='TESTUPDATE'
WHERE col1=3023481
GO
UPDATE Test_GUID SET col1=232342,col3=232340,col4='TESTUPDATE'
WHERE col1='FA7B4737-70ED-49EA-BD26-19B737294C9D'
GO
UPDATE Test_VARCHAR SET col1=232342,col3=232340,col4='TESTUPDATE'
WHERE col1='FA7B4737-70ED-49EA-BD26-19B737294C9D'
GO
-- DELETE
DELETE FROM Test_INT WHERE Id=2789341
GO
DELETE FROM Test_GUID WHERE Id='477F0D8E-9B70-4573-8E67-006FC7797C27'
GO
DELETE FROM Test_VARCHAR WHERE Id='0055E12C-2095-4166-83B5-719B9A2957D0'
GO
Run one SELECT statement and compare the values for total execution time. Query -> Include Client Statistics (SHIFT + ALT + S). Query -> Include Actual Execution Plan (CTRL + M).
After running each of these queries several times and comparing resource costs and Total Processing Time, they are pretty much on the same order. However, as we grow the index, this can impact performance negatively as we've seen in production and the DBAs have had to intervene by rebuilds/reorganize.
Having high average index fragmentation doesn't necessarily mean that performance is negatively impacted, it depends on the queries and the execution plan. If the operations used causes index/table scans can (a fragmented index could be more prone to this). A seek will only hit pages that contain these qualifying rows.
TBD
Considerations
Choice of a primary key depends on the situation. There are times where a VARCHAR or UniqueIdentifier could be an appropriate choice. These situations seem rare. A single table that has no relationships and inserts/updates/deletes/selects don't occur often. The table is expected to be small.
Use of a VARCHAR or UniqueIdentifier datatype for PK uses more memory and does not auto-increment.
Having an auto-incrementing numeric identity primary key along with a UniqueIdentifier external ID is an ok compromise.
References
- mssqltips.com/sqlservertip/5105/sql-server-..
- stackoverflow.com/questions/332300/is-there..
- sqlperformance.com/2017/06/sql-plan/perform..
- dataschool.com/sql-optimization/how-indexin..
- stackoverflow.com/questions/337503/whats-th..
- sqlshack.com/sql-database-design-choosing-p..
- blog.codinghorror.com/primary-keys-ids-vers..
- tomharrisonjr.com/uuid-or-guid-as-primary-k..
- sqlshack.com/how-to-identify-and-resolve-sq..
- docs.microsoft.com/en-us/sql/relational-dat..
- iq.opengenus.org/b-tree-search-insert-delet..
- brentozar.com/archive/2012/08/sql-server-in..
- sqlperformance.com/2017/12/sql-indexes/impa... -social.technet.microsoft.com/wiki/contents/..
- blog.sqlauthority.com/2007/03/30/sql-server..